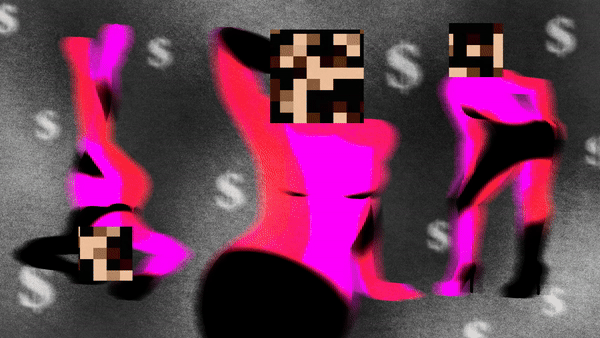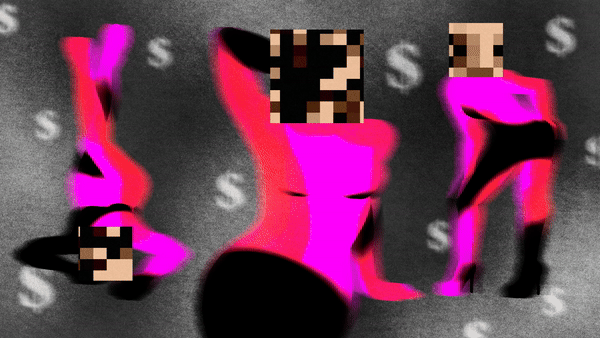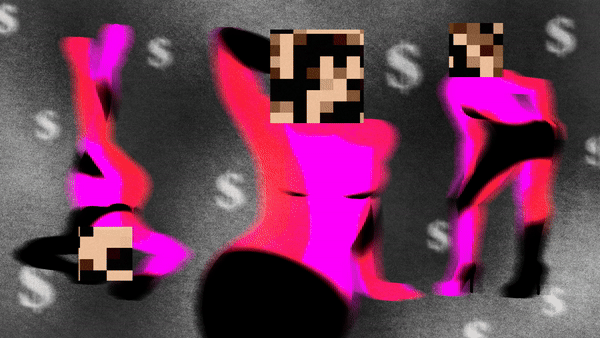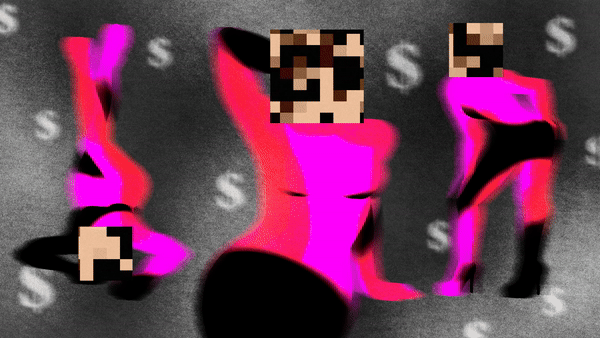Μεγέθυνση κειμένου
Ένα δημοφιλές σύνολο δεδομένων εκπαίδευσης Τεχνητής Νοημοσύνης «κλέβει και χρησιμοποιεί ως όπλο» πρόσωπα παιδιών από το διαδίκτυο χωρίς αυτά να το γνωρίζουν
Πάνω από 170 εικόνες και προσωπικά στοιχεία παιδιών από τη Βραζιλία έχουν αποσπαστεί από ένα σύνολο δεδομένων ανοικτού κώδικα χωρίς τα ίδια και οι οικογένειές τους να το γνωρίζουν – και χωρίς φυσικά τη συγκατάθεσή τους – για την εκπαίδευση της Τεχνητής Νοημοσύνης (AI).
Σύμφωνα με νέα έκθεση του Παρατηρητηρίου Ανθρωπίνων Δικαιωμάτων που δημοσιεύθηκε στις αρχές Ιουνίου του 2024, οι εικόνες συλλέχθηκαν από περιεχόμενο που αναρτήθηκε από τα μέσα της δεκαετίας του 1990, πολύ πριν οποιοσδήποτε χρήστης του διαδικτύου προβλέψει ότι το περιεχόμενό του θα κινδύνευε να χρησιμοποιηθεί από τρίτους, μέχρι και το 2023.
Το Παρατηρητήριο Ανθρωπίνων Δικαιωμάτων ισχυρίζεται ότι τα προσωπικά στοιχεία αυτών των παιδιών, μαζί με τους συνδέσμους URL των φωτογραφιών τους, συμπεριλήφθηκαν στο LAION-5B, ένα σύνολο δεδομένων που αποτέλεσε δημοφιλή πηγή εκπαίδευσης για νεοφυείς επιχειρήσεις Τεχνητής Νοημοσύνης.
«Η ιδιωτική τους ζωή παραβιάζεται σε πρώτη φάση όταν η φωτογραφία τους σαρώνεται σε αυτά τα σύνολα δεδομένων. Στη συνέχεια τα εργαλεία Τεχνητής Νοημοσύνης εκπαιδεύονται σε αυτά τα δεδομένα για να μπορούν να δημιουργήσουν ρεαλιστικές εικόνες παιδιών», λέει η Hye Jung Han, ερευνήτρια για τα δικαιώματα των παιδιών στο Human Rights Watch.
«Η τεχνολογία έχει αναπτυχθεί με τέτοιο τρόπο ώστε κάθε παιδί που έχει φωτογραφίες ή βίντεο του εαυτού του στο διαδίκτυο να κινδυνεύει πλέον, επειδή οποιοσδήποτε κακόβουλος φορέας θα μπορούσε να πάρει αυτή τη φωτογραφία και στη συνέχεια να τη χρησιμοποιήσει όπως θέλει».
Μία τεράστια πηγή AI εικόνων
Το LAION-5B βασίζεται στο Common Crawl, ένα αποθετήριο δεδομένων που δημιουργήθηκε συλλέγοντας διάφορα στοιχεία από το διαδίκτυο μέσω bots – μία διαδικασία που ονομάζεται web scraping ή ιστοσυγκομιδή – και τέθηκε στη διάθεση των ερευνητών. Δημιουργήθηκε από τη γερμανική Μη Κερδοσκοπική Οργάνωση LAION, είναι προσβάσιμο σε όλους και περιλαμβάνει πλέον περισσότερα από 5,85 δισεκατομμύρια ζεύγη εικόνων και λεζάντες, σύμφωνα με τον ιστότοπό του.
Οι εικόνες των παιδιών που βρήκαν οι ερευνητές προέρχονταν από mommy blogs και άλλα προσωπικά ιστολόγια, καθώς και φωτογραφίες από βίντεο στο YouTube με μικρό αριθμό προβολών, που φαίνεται ότι ανεβάζουν οι χρήστες για να μοιραστούν με την οικογένεια και τους φίλους τους.
Ο εκπρόσωπος της LAION, Nate Tyler, λέει ότι ο οργανισμός έχει ήδη αναλάβει δράση. «Το LAION-5B κατέβηκε ως απάντηση σε μια έκθεση του Στάνφορντ που βρήκε συνδέσμους στο σύνολο δεδομένων που παρέπεμπαν σε παράνομο περιεχόμενο στον δημόσιο ιστό», αναφέρει, προσθέτοντας ότι ο οργανισμός συνεργάζεται επί του παρόντος με το «Ίδρυμα Internet Watch, το Καναδικό Κέντρο Προστασίας Παιδιών, το Στάνφορντ και το Παρατηρητήριο Ανθρωπίνων Δικαιωμάτων για να αφαιρέσει το παράνομο περιεχόμενο».
Το πρόβλημα των deepfakes στα σχολεία
Οι όροι παροχής υπηρεσιών του YouTube δεν επιτρέπουν το web scraping παρά μόνο υπό ορισμένες συνθήκες. Οι συγκεκριμένες, ωστόσο, περιπτώσεις φαίνεται πως παραβιάζουν αυτές τις πολιτικές. «Ήμασταν ξεκάθαροι ότι το μη εξουσιοδοτημένο scraping περιεχομένου του YouTube αποτελεί παραβίαση των Όρων Παροχής Υπηρεσιών μας», λέει ο εκπρόσωπος του YouTube, Jack Maon, «και συνεχίζουμε να λαμβάνουμε μέτρα κατά αυτού του είδους κατάχρησης».
Τον Δεκέμβριο του 2023, ερευνητές του Πανεπιστημίου του Στάνφορντ διαπίστωσαν ότι τα δεδομένα εκπαίδευσης AI που συλλέχθηκαν από το LAION-5B περιείχαν υλικό σεξουαλικής κακοποίησης παιδιών. Το πρόβλημα των deepfakes αυξάνεται ακόμη και μεταξύ των μαθητών σε σχολεία των ΗΠΑ, όπου χρησιμοποιούνται για να εκφοβίζουν συμμαθητές τους, ιδίως κορίτσια.
Η Hye ανησυχεί ότι, πέρα από τη χρήση παιδικών φωτογραφιών για τη δημιουργία CSAM (Child Sexual Abuse Material – πορνογραφικό υλικό με παιδιά), η βάση δεδομένων θα μπορούσε να αποκαλύψει δυνητικά ευαίσθητες πληροφορίες, όπως τοποθεσίες ή ιατρικά δεδομένα.
Το 2022, μια καλλιτέχνιδα με έδρα τις ΗΠΑ βρήκε τη δική της εικόνα στο σύνολο δεδομένων LAION και συνειδητοποίησε ότι προερχόταν από τον ιδιωτικό ιατρικό της φάκελο.

Οι κίνδυνοι από τις φωτογραφίες και τα βίντεο των παιδιών στο διαδίκτυο
«Τα παιδιά δεν θα πρέπει να ζουν με τον φόβο ότι οι φωτογραφίες τους μπορεί να κλαπούν και να χρησιμοποιηθούν ως όπλο εναντίον τους», λέει η Hye, η οποία υποστηρίζει πως οι εικόνες που ανακάλυψε η ίδια και η ομάδα της ανήκει σε λιγότερο από το 0,0001% όλων των δεδομένων στο LAION-5B. Υποψιάζεται, δε, ότι είναι πιθανό παρόμοιες φωτογραφίες να υπάρχουν στο σύνολο δεδομένων από όλο τον κόσμο.
Το 2023, μία γερμανική διαφημιστική καμπάνια χρησιμοποίησε ένα deepfake που δημιουργήθηκε από Τεχνητή Νοημοσύνη για να προειδοποιήσει τους γονείς να μην αναρτούν φωτογραφίες των παιδιών τους στο διαδίκτυο, προειδοποιώντας ότι οι εικόνες των παιδιών τους θα μπορούσαν να χρησιμοποιηθούν για να τα εκφοβίσουν ή να δημιουργήσουν CSAM.
Αυτό όμως δεν αντιμετωπίζει το ζήτημα των εικόνων που έχουν ήδη δημοσιευτεί ή είναι από παλιότερες δεκαετίες, αλλά εξακολουθούν να υπάρχουν στο διαδίκτυο.
«Η αφαίρεση των συνδέσμων από ένα σύνολο δεδομένων LAION δεν αφαιρεί αυτό το περιεχόμενο από τον ιστό», λέει ο Tyler. Αυτές οι εικόνες μπορούν να βρεθούν και να χρησιμοποιηθούν, ακόμη και αν αυτό δεν γίνεται μέσω του LAION. «Αυτό είναι ένα ευρύτερο και πολύ ανησυχητικό ζήτημα και ως Μη Κερδοσκοπικός, Οργανισμός, θα κάνουμε το χρέος μας για να βοηθήσουμε».

Η Hye λέει ότι η ευθύνη για την προστασία των παιδιών και των γονέων τους από αυτού του είδους την κακοποίηση βαρύνει τις κυβερνήσεις και τις ρυθμιστικές αρχές. Το νομοθετικό σώμα της Βραζιλίας εξετάζει επί του παρόντος νόμους για τη ρύθμιση της δημιουργίας deepfake, ενώ στις ΗΠΑ, η εκπρόσωπος Alexandria Ocasio-Cortez από τη Νέα Υόρκη έχει προτείνει τον νόμο DEFIANCE Act, ο οποίος θα επιτρέπει στους ανθρώπους να υποβάλλουν μήνυση εάν μπορούν να αποδείξουν ότι ένα deepfake με το ομοίωμά τους είχε δημιουργηθεί χωρίς συναίνεση.
«Νομίζω ότι τα παιδιά και οι γονείς τους δεν θα πρέπει να επωμιστούν την ευθύνη για την προστασία των παιδιών από μια τεχνολογία από την οποία είναι ουσιαστικά αδύνατο να προστατευτούν», λέει η Hye. «Δεν είναι δικό τους λάθος».
Με πληροφορίες από Wired

Ακολουθήστε το pride.gr στο Google News και ενημερωθείτε πρώτοι




Νεοτερα